

[all pages:] introduction tscore cwn mugraph sigadlib signal score2sig utilities references [site map]
All pages: introduction tscore cwn mugraph sigadlib signal score2sig utilities references [site map]
|
|
|
|
| introduction | BandM muSig | cwn |
bandm tscore, a Framework for Denotating Temporal Structures
1
Fundamentals
1.1
Intentions and Basic Ideas
1.2
Text Input and Editing
1.3
Layered Architecture, Project Strategy, and Structure of this Text
2
Structure of the Raw Model and Syntax of the Raw Front-End Representation
2.1
Model Elements and Their Basic Relations
2.2
Structural Hierarchy of the Input Text
2.3
Timelines and Timepoint Objects
2.4
Voicelines
2.4.1
Voice Lines and Lexical Entities
2.4.2
Parentheses in Voice Lines, Not Crossing Time Line Time Points
2.4.3
Parentheses in Voice Lines, Freely Crossing Time Line Time Points
2.4.4
Cascaded Divisions
2.4.5
Full Compositionality of Time Division
2.4.6
Dotted Notation
2.4.7
Application
2.5
Parameter Lines
3
Current State of the Implementation
3.1
Test and Demo Execution
tscore is a framework for writing down textual representations of
diachronuous data.
Its original purpose is to denotate musical structures,
supporting a multitude of stylistic and historic paradigms. But due to its
generic structure, the denotated data
can be of more varying formats and semantics, as long as
its primary domain is any ordered, one-dimensional domain,
like "duration" or "time points".
This time-related-ness is what the letter "t" in tscore stands for.
1
Examples for these kinds of data are ...
To achieve utmost genericity,
tscore is a layered software product: The first two layers,
seen in the direction of work-flow, are (1) a parser for
the front-end notation, and (2) a computer internal
data model serving as the parser's output format.
This parsing algorithm and this data model are referred to as "raw" in the following.
The semantics of the input data are not defined by this raw level,
but by subsequent parsing and processing defined by the user.
Nevertheless, there must be a minimal set of common interpretation rules, already ruling the "raw" level. The most important of these is that the basic layout of the input text follows the principles of classical western music notation, short CWN:
Making the visual horizontal position the basis for denotating timing information, we try to resemble the usual structure of musical scores as close as possible. We think this much more convenient for a musician to read as well as to write than is an expression-like language, as used by e.g. LilyPond, musixTeX and many other music input formats. 2
As mentioned, the input format is a text file, and the
horizontal position of lexical entities is significant.
Therefore writing and editing tscore input files requires
an editor with monospace input font.
The starting column number of any lexical entity
will be related to the starting position
in some time domain, and this column number will be calculated
based on equi-distant character positions.
Wrapping lines must be avoided, so the editor window should contain approx. 170 columns
Furthermore, a kind of "intelligent tabular input mode" would be very useful,
which would allow to insert/delete text in one line, and keeping all
other lines of the same accolade in sync by automatically inserting/deleting
white space accordingly.
(This can be relatively easy be enhancing an emacs/xemacs tabular mode, but
is still t.b.d.)
The tscore software in a first stage addresses programmers who
want to establish their own time-based input language, according to
the above-mentioned conventions, as convenient as possible.
(Indeed we have employed simple, but not too simple prototypical examples
the syntax, semantics and output generation of which fits together on one printed page !-)
The following text describes the fundamental principles of design and operation. It is accompanied by the API documentation , which should be referred to whenever appropriate.
The first two raw layers, parser and data model as mentioned above, try to be as neutral to any meanings or fine-granular syntax as possible. Semantics must be introduced into the processing stack by the user, defining transformations performed by subsequent processing steps.
To support this, there is a (constantly growing) collection of library functions, providing basic functionality like time filtering, pitch tuning, pattern instantiation, etc. These must, nevertheless, be employed by the user explicitly to achieve the intended semantics.
The basic strategic idea of this project is currently, that in a first phase a collection of applications is hard-coded in form of Java classes' source text.
In a second project phase the front-end language shall be enhanced step by step with constructs allowing to "plug together" and parametrize the above-mentioned basic libraries, so that the user in a later stage of the project can specify the score processing without the need to use the Java language.
In the next sections first the basic mechanisms of the raw level of tscore will be explained.
Above that raw level, there is already a first application, dealing
with Common Western Notation. This is realized by the class
Score_cwn .
This class in turn relies on basic entities, which all
are contained in the packages
music/entities and
music/transform .
The later sections of this text ([label txt_cwn not found ???])
will use this application
as a further example for explaining the tscore basic paradigms,
and in the same course explain this first instantiation itself, for any user who wants
to employ it directly.
This is sensible because (1) while being restricted to CWN as the
format of both the input and the resulting data model, the Java code
is still totally open w.r.t. the interpretation and further processing
of the data, and (2) the Java source text can be taken as a template
and expanded to the user's needs.
The projects source tree reflects this layered approach and is roughly described as follows:
The tscore raw data model consists of the classes ...
The central notion is that of Event.
The basic relations are ...
Event = voice:Voice
* when:Tp
* params: string -/-> P Param
|
Seen the other way, each voice is a "sequence of" events. It is important that a voice is "monodic", ie. it holds that the following map is bijective ...
(Voice * Tp) >-/-> Event |
Each event is identified by only one certain combination of voice and time point unambiguously!
On this raw layer, each parameter value does not carry any semantics, but only the text string from the input file:
Param = unparsed:string |
The semantic interpretation of parameters must be realized in a "user model" of a score by additional, explicitly created and well-typed "map" constructs, as given here as an example:
MyTonalScore = ... * pitches:(Event->TonalPitchClasses)
* volume:(Event->MusicalLoudness)
* ...
|
Additionally and independently, each event can be member of many event sets.
EventSet = events:P Event |
Representing the fundamental object classes and their relations as a graph makes clear that Event is the central class for the organization of the model:
+----------+
| Tp |
| |
+----------+
1 ^
|
* |.when
+--------+ 1 * +----------+ * <.contains *+--------+
| Voice |<--------| Event |---------------|EventSet|
| | .in | | .memberOf> | |
+--------+ +----------+ +--------+
* |.params
|
* V
+------+
| .name|
+------------+
| Param |
| |
+------------+
|
Parts are a means for breaking the front-end notation (as contained in an input file) into pieces of manageable size, but do not appear in the model, once the input files are parsed. Any grouping or adressing of events is done exclusively by their timepoints or by explicitly constructed event sets.
Similar, all higher level grouping, like sets of event sets, sets of voices, sets of params, etc., can of course be defined by the user atop of this basic model, but are intentionally left out of the raw core definitions.
The model elements' class definitions are all contained in the tscore/model package. Their sources are generated from the "tscore.umod" model definition file.
Currently the input texts are organized in the follwing hierarchy, where each object of a certain level consists of those of the next lower level, in the indicated multiplicity:
file | FORMAT * | PARS * | | accolade + | | | timeline 1 | | | VOX + | | | | parameterline * |
Roughly spoken: each file consists of parts, which consist of accolades, which consist of voices, which consist of parameter lines.
The top-level grammar is:
| tscore_file ::= formatDef partDef |
| formatDef ::= FORMAT ident EXTEND ident = formatSpec |
| formatSpec ::= // defines parsing rules for use with subsequent data sections |
| formatUse ::= CONFORM ident |
Each file may contain FORMAT definitions which direct, configure and parametrize the parsing process of those subsequent parts and voices in which they are referred to by some formatUse statement.
((
This feature is not yet implemented.
It is foreseen mainly for a front-end representation of the
"high-level plugging-together", which will replace the Java-level
glueing code in future stages of this project, see Section 1.3 above.
In this context a kind of "include" directive
for including source files seems usefule, to support
the re-usage of these format definitions.
Additionally, as mentioned above,
in future more input formats seem sensible, as alternatives to the
"horizontal parts", e.g. "vertical parts" and "finite discrete maps".
These can also be selected by such a CONFORM directives.
))
The main data is contained in partDef s.
|
partDef ::= PART
ident
formatUse
accolade |
The following input lines are taken as the contents of this part and parsed on a line-by-line discipline. In this process, as mentioned above, the horizontal starting position of all input particles is significant, and is interpreted as position in time.
The begin of each accolade in this part is indicated by its (one and only) timeLine. Time lines, voice lines and parameter lines are again clearly recognizable by leading reserved words:
| accolade ::= timeLine voice |
| timeLine ::= T timeConst . subDivision timeConst |
| subDivision ::= ! . |
| voice ::= voiceLine paramLine |
|
voiceLine ::= VOX
ident
formatUse
element |
| paramLine ::= P ident element |
All these dependencies will be explained in detail in the following sections, using examples.
The meaning of a timeline is to establish a relation between selected text columns ("x coordinates") and time point values from the model world.
This relation is valid for the whole accolade, and controls the interpretation of the column position for all subsequent lines, up to the next timeline. Nevertheless, it is only a first and coarse relation and can be further subdived by each voiceline individually.
After the leading identifier "T", each timeline contains a sequence of top level time constants. Between these, exclamation marks "!" can be interspered for further division, and between these dots "." for an again finer sub-division.
In most cases the top level time constants will be of numeric type. But this is again related to the subsequent, user-defined processing step. The raw parser allows arbitrary numbers, and even alphanumeric identifiers:
Eg. a "score" like
PARS RennsteigWanderung T Eisenach . ! . . ! . Oberhof VOX Leitung MD ML MD MD ML VOX Hotel ?? "Thüringer Hof" |
...could represent a "hiking schedule" with overnight stays ("!") and rests during day time (".").
But normally the top level time constants will be numeric, and normally even further constrained, e.g. to be integer, to be in ascending order, or even to be adjacent.
The time points in the internal model are based on "division" as means
of construction:
In the case of a time line this is straight forward:
For each top level time constant, a time point value is defined.
For each two directly subsequent top level time constants
a "division" object is constructed, containing as many new time points as
there are exclamation marks in the input.
(Thus the number of the segments the original distance is splitted into is
one(1) larger than the number of exclamation marks!)
This process is applied recursively to the dots between exclamation marks
and to the dots between exclamation mark and time constant(s).
(The same process will then be applied to the events
and parenthesized groups in the main parameter line of a
voice line, which fall between two such time markers, and to the
contents of these paraenthesized groups. This is described below.)
Time point objects in the model world are terms with algebraic semantics which can be described by the formula ...
Tp_0 = string // top level, arbitrary text as its value Tp_1 = Tp_0 + DIV(Tp_0, Tp_0) Tp_2 = Tp_1 + DIV(Tp_1, Tp_1) Tp_3 = Tp_2 + DIV(Tp_2, Tp_2) Tp_<L+1> = Tp_L + DIV(Tp_L, Tp_L) // for arbitrary L DIV(T) = T * T * n * k // with 2<=n and 0<k<n, // n being the division factor and k being the selected position |
For those who prefer UML diagrams:
+------------------+ 1 from +-----------------+
| Tp | <-------------| TDiv |
| | <-------------| div:int |
+------------------+ 1 to +-----------------+
/_\ ^
| |
+--------------------------- |
| | |
+------------------+ +-----------------+
| TpTop | | TpSub |
| | | pos:int |
+------------------+ +-----------------+
|
The realizing Java classes are part of the raw model,
see Section 2.1 above.
Each time point is realized as an instance of the
tscore/model/Tp class.
Its sub-classes are
TpTop for top level
timepoints, and
TpSub.
The latter are related to two(2) higher-level time points by a
TDivision object.
Please note that only the foreseen factory methods may be used to
create instances of these classes, because they make heavy use
of cons-caching!
This requires always the existence of one global object of class
TimeScape,
which serves as the repository for the top-level time points.
All sub-classes of Tp provide all methods needed for
creating divisions and retrieving time points.
But operating on this level is tedious. So one of the first steps
in any user transformation is translating these merely formal time positions
into some user-level semantic model of time, e.g. metrical time in the
sense of CWN.
For this purpose there is a growing collection of transformation libraries. Consquently, these are not contained in the sub-packages of tscore , which deals with the raw data, but in the package music/transform , which deals with certain semantics.
But also for the user it is important to notice that "raw / front-end time points" is a mere technical data type, related to the input format, and does not imply any semantics, like "numeric division" or "rational numbers". Consequently, no properties like "equi-distance" or "normal form" are defined by the raw data model, and the subsequent interpretations may impose very different meanings!
E.g. in the example
PARS p1 T 1 ! ! ! 2 VOX v1 X1 PARS p2 T 1 ! 2 VOX v2 X2 |
... event X1 happens at the second position of a division by four between timepoints "1" and "2", and X2 happens at the only position of a division by two between the same timepoints. But this only holds for the input text, not always for the intended semantics!
Of course, when an applications maps the "textual division" to the division of durations, using rational numbers, then the meaning of these both time points will result to the same value in the domain of time instances, they will fall together in the same way as "2/4=1/2" holds.
But this is not necessarily so!
If the example is part of a kind of "cue list", then it could read
in a quite different way, which may seem peculiar to laymen but perfectly common
to domain experts, e.g. in an additive way: "X1 is two decimeters behind marker 1" and
"X2 is one decimeter behind the same marker"!
Or there could be contexts in which the division is performed logarithmically, or in some even more fancy way.
Another example:
It is easy to see that a notational pattern like
T 1 . . ! . ! . 2 . . ! . ! . 3 |
can be used for both the following, very different metrics in the same sensible way:

Which of both is really meant, that is up to the subsequent transformation steps,
and NOT defined in the raw data model discussed here!
Instead, the raw parser (when parsing time lines and voice lines),
simply constructs elements of the
tscore/model/Tp class,
according to its technical interface, and passes this data to the
subsequent, user-defined processing steps.
The identifier appearing after the leading key word "VOX" gives the name of the voice. Theoretically the same voice could appear more than once in the same accolade. But since each voice may have maximally one(1) event per time point, this is hardly sensible.
The rest of the line (up to the next reserved word "T", "VOX", or "P", see the grammar rules above) contains lexical entities. These are translated into events, thus making up the contents of the voice.
Indeed, this part of the voice line has a two-fold function: First it defines a new event simply by the x-coordinates at which a new lexical element starts. It calculates a time point according to this coordinate, based on the relation of x-coordinates to time points as defined by the currently valid time line, by applying the same division principle as in time line definitions.
Then it creates a new "Event" object in the current voice, and assigns this time point to it as its ".when" value.
Secondly, it takes the concrete content of the lexical entity and stores it as the value of a first, implicitly given parameter track. This parameter is the "generating parameter". In contrast to other parameters, it is never optional, but always required. There is one single generic name for this parameter, currently "$main".
In most cases of representing traditional music, the generating parameter will be some kind of "pitch representation", simply because this is the primary dimension of any melodic structure, as in ...
PARS CpI T 1 2 3 ! 4 ! 5 VOX Alt a d f d cis d e f - g f e d |
But this is not required, eg. as in ...
PARS schlagzeug T 1 2 3 VOX drumset x x xo xo x - ! xo |
Please note that voice lines apply the division mechanism again, like the time lines described above, respecting the definitions already established. In the following variant ...
PARS schlagzeug T 1 ! 2 ! 3 VOX drumset x x xo xo x - ! xo |
...the time line defines a division into two(2) segments between each top level time constants. The voiceline further divides each first segment of these divisions into three(3) segments by placing three(3) events into the textual space!
Attention:
The "parameter tracks" defined below translate vertical alignment into synchronicity.
This is not the case with the VOX structures: every such divides the
vertical text tiles as defined by the T-line independently.
So in the following diagram, score (A) is the exaclty the same as (B).
In CWN, with its metrical time model and the
hold operator "-", their effect is a "two against three" polyphony, as described by
(C), and not two sychronuous events as described by (E),
what probably has been intended, misled by a confusion of VOX and P layers.
(The authors themselves stepped into this trap more than once !-)
For denotating (E), the form (D) is convenient.
(A) (B) (C) T 1 2 T 1 2 T 1 2 VOX a O M U VOX a O M U VOX a O - - M - - U VOX b U O M U VOX b U O M U VOX b U - O - M - U (D) (E) T 1 ! 2 T 1 2 VOX a O M U VOX a O - M - U VOX b U O M U VOX b U - O M U |
The lexical entities contained in a voice line (and in the subsequent parameter lines, see Section 2.5) are combinations of arbitrary characters. There are hardly any rules or limitations. Eg., non-alpha-numeric identifiers like "-" and "<" can be defined and used nearly totally free. The parsing of the "inner structure" of all lexical entities is done in a later processing step, by user-defined code, dedicated to a certain score format. (To support this, a collection of library functions is provided, the user simply can plug together.)
The raw parser simply collects the character data of all voice lines and parameter lines and stores them for this later parsing process, indexed by events and by parameter names.
On the raw parsing level, only a few characters are reserved and have special meaning as separator characters, namely,
Lexical entities thus may be ...
Consequently, the lexical entities of the first three kinds are always terminated by their dedicated closing character, and those of the last kind are always limited by a separator character.
Each continguous group of non-parenthesized lexical entities
(i.e. each sequence of lexical entities of type 2 to 4
not separated by intervening whitespace)
creates exactly one(1)
new event in the current voice.
For the contents of parentheses the same rule applies recursively,
but the construction of TimePoints is defined differently, as described below.
So the following text in a voice line
VOX alt <&%"text string"@fun(param)34;-??? 17 |
will create two(2) events, and the text strings
"<&%"text string"@fun(param)34;-???"
and "17"
will be assigned to their main parameter, respectively.
Iff the start column of the textual representation of an event is already linked to a time point, defined by the contents of the time line, then the event is simply related to this time point as its ".when" coordinate.
Otherwise one or more events lie between two(2) time points from the time line, and their respective text input columns. In this case a TpDivision is created for these two time points and for the number of sub-intervals, needed for the events. The events are then assigned to the TpSubs from this division, in sequential order of their start columns. This process of sub-division is the same as in the time line itself, when placing exclamation marks between top-level timepoints or dots between exclamation marks.
It is not allowed to place an event between two definitions points of the measure line without also placing an event exactly at the left of both. This is meant as a check for plausibility and readability.
Therefore, for "hopping over" a time point defined in the time line, the definition of the generating parameter must include some "dummy" or "rest" symbol, which will be thrown away during the subsequent semantic interpretation-
E.g. the pitch parameter of "common western notation" ("CWN") defines a symbol for pause "%" and a hold symbol "-", useful for this purpose, as to be seen in ...
T 17 ! ! 18 // forbidden: VOX soprano a b c d // allowed: VOX soprano a - b % c d |
The column containing "c d" demonstrates clearly the impact small typos could have without this rule!
Sequences of lexical entities contained in parentheses, where the textual extension does not cross a time point definition from the time line, are treated as follows:
In the first step, when calculating the new divisions introduced by the lexical entities and the corresponding events, the whole parenthesized term is treated as one(1) single entity.
After its start point and that of its successor event is calculated, the division algorithm is applied recursively on the content of the parentheses and to these both time points.
For example, in ...
T 1 2 VOX soprano a (b c) |
...the event "a" is placed at time point "1",
the event "b" is placed at first(and only) division by two(2)
between the top level time points "1" and "2",
and the event "c" is placed at first(and only) division by two(2)
between the time point of "b" and top level time point "2"-
Similar, the notation
T 1 2 VOX soprano a (b(c d)e) |
means, when interpreting the top level time points as sequence of bars
in 2/4 measure, simply
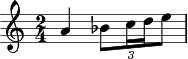
... a thing we assume to be intuitively clear for a skilled musician, already when looking at the textual input above.
More complicated is the situation when the contents of a parenthesized expression covers horizontal space which does include time point definitions from the time line.
In this case the the division algorithm is applied in a similar way, but in the first step independently for the opening and the closing parenthesis. The second step, the division for distributing the contents, then happens in the same way as in the simple case.
Of course, this is not always sensible or even easily readable. But it is simply the canonical continuation of the more simple rule from above!
Eg. in
T 1 2 3 VOX soprano a (b c d) e |
...first "bar 1" and "bar 2" are divided into two(2) segments each,
namely for the top level
events "a" resp. "e", and for that part of the
parenthesized expression which reaches into their horizontal space.
So the parenthesized expression is defined to begin at the
second division point in "bar 1" and end at the second division point
in "bar 2", ant the contents is distributed to further division points
between these two time points.
Please note that in the internal data model of time points this is the first case when a division is spanned between two time points which are not "neighbours" in the preceding generation!
Applying again "normal metrical interpretation" of a 2/4 metric to this
example, the result is still rather sensible and readable, namely a syncopated triad:

Of course, as a simple consequence of the described rule,
the graphical positions of lexical entities inside
the parentheses is not related to the definitions from the
time line! The "c" event in the example above is exactly below
the "2" from the time line merely by chance. This has no meaning,
because the events inside the parenthesis are distributed to the
newly created division points, according to the number of lecixal
entities and the two bounding time points.
The following inputs would all have exactly the same result:
T 1 2 3 VOX soprano a (b c d) e // or T 1 2 3 VOX soprano a (b c d) e // or T 1 2 3 VOX soprano a(b c d) e |
Of course, you can easily denotate divisions which are not easily readable anymore, or even not expressible by standard western notation. One simple character suffices:
T 1 2 3 VOX soprano a (b c d) e f |
Again under the same interpretation, this results in a triplet which has to be
distributed over a quater PLUS a triplet quater.
This is something like "nine to five", and I do NOT want to figure out
the corresponding lilypond source expression,
but simply provide a manual rendering instead:
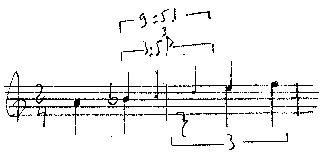
Of course one can think further: A linear nesting of arbitrary depth is always possible, e.g. for representing renaissance "musica colorata", etc.
T 1 2 VOX soprano a (b c (a b d c e)) a |
This is a quintuplet in a triplet, which is nothing unusual in this time.
T 1 ! ! 2 VOX soprano a (a b c d e) a |
This is a quintuplet over TWO(2) segments of a triplet, which is still quite usual.
The last construct from the preceding section, and the "nine to five" from further above, can currently only be expressed by the co-operation of the time line and some voice line!
A future version of this program could perhaps support
fully compositional time division, so that arbitrary sums of segments
can again be divided arbitrarily.
A possible front-end solution could be ...
T 1 ! ! 2 3 VOX soprano a ! g // NOT YET supported: TT ( ! ! ) ! VOX alt a b c d TTT ( ! ) |
Please note that this is currently not possible to DENOTATE, due to the parser, while the raw data model indeed is fully compositional and DOES support all the required values!
One thing the user acquainted to CWN does not want to miss is
dotted notation.
It is used for "sharpening" the duration proportion of two adjacent events.
In most contexts its effect is to replace the equidistant subdivision of a
certain time interval "1:1" by the proportion "1:3" or "3:1" (one dot)
or "1:7" or "7:1" (two dots), etc.
3
In traditional notation, the dot(s) behind the head of a certain note (or behind a pause symbol) adds 1/2, 3/4, 7/8 etc, to its original duration, and the other, adjacent note (or pause) must be explicitly shortened accordingly.
The tscore base library contains the class tscore/base/DottedNotationExpander. ( Please note that this transformation class is in the generic tscore package and not where you could expect it, in the CWN specific music/transform package. This is because the dotted notation comes from CWN, but can be applied to all kinds of voice lines, whenever the user considers appropriate. )
This parses the "event generating" $main parameter of a
voice line, recognizes dot symbols, and does
both these modifications in one step: It re-adjusts the
proportion of the "raw" time points
of two adjacent events, extending the one duration and shortening the other
simultanuously.
It also deletes the dots from the input text, so that the subsequent parsing
of the "$main" parameter will not be affected.
The dot symbol must stand between the two affected events, ie. between their lexical representation in the voice line. It must be separated by whitespace only from one of them, and directly attached to the other. This attached one will be prolongated, the separated one will be shortened.
So the following notation
T 1 2 3
VOX alt1 a. b
VOX alt2 a .b
|
is equivalent to
T 1 2 3
VOX alt1 a - - b
VOX alt2 a b - -
|
and to
T 1 2 3
VOX alt1 a (- b)
VOX alt2 (a b) -
|
This works also when the shortened part is a parenthesized groups, and even recursively:
T 1 2 3
VOX alt1 a. (b c)
VOX alt2 a. (b. c)
|
Please note that always the later event is re-adjusted in time. So its time position must not be defined by a time-point of the time-line, because such a time point is considered to be "defined", ie. "fixed" and "not movable".
// NOT allowed:
T 1 2 3
VOX alt3 % a. b
VOX alt4 % a .b
|
Also not allowed are dots which relate two events from different sub-divisions. But this is the same in classical notation:
// NOT allowed:
T 1 2 3
VOX alt (a b.) c
|
What hurts more is that a dotting cannot cross time points from the time line. Brahms preferred (for the famous syncopations in his symphonies) the dot notation which even crosses bar lines. This is allowed in the romantic phase, but regretably not with tscore:
// NOT allowed:
T 1 2 3 4
VOX alt a b. c d. e f
|
The "application" construct is a means to tie a complex syntactic structure to one single event, resp. parameter value.
Its syntax is basically
| application ::= @ ident ( argument , argument ) |
| argument ::= ident = argumentValue |
| argumentValue ::= // ANY sequence of characters not containing "," or ")" |
This allows more complex expressions to be "tunneled" through the position-aware tokenization of the front-end, as in
T 120 121 122 123 124
VOX sopran c cis @siegfriedMotiv(tempo=viertel, tonart=C-dur,
lastNote=1/2)
d dis e f
|
As mentioned above, the raw parsing process creates a data structure which relates events to un-parsed parameter values, as in
Event = voice:Voice
* when:Tp
* params:(paramName:string -/-> P Param)
Param = unparsed:string
|
Every combination Event*ParamName may point to more than one Param object, because in the original score there may be more than one line with the same parameter name. These string values are concatenated (separated by whitespace!), and then undergo the user defined "fine" parsing process.
As already explained, the lexical entities contained immediately in a voice line cause the generation of new events, but nevertheless are normal "raw" parameter values like those in the following parameter lines. The only differences are
Esp. the second point is crucial. A frequently happening situation (esp. in "romantic" music) is a cresc./dim. structure like
T 12.0 13.0 VOX sopran fis - % P dyn < > ! |
In a printed output there would be a WHOLE note with a cresc. and a decresc. extending over a HALF note each. For this to be definable, already the voice line must provide for the two half notes. The following notation is not legal:
// NOT allowed T 12.0 13.0 VOX sopran fis % P dyn < > ! |
The alternative, allow parameter tracks to create new time points, could lead easly to very confusing situations for which simple semantics cannot be defined anymore. E.g., what would be the meaning of
// NOT allowed T 12.0 13.0 VOX sopran fis % P dyn < > ! P artic _ _ |
Does this mean a hierarchy of parameter lines? Or a kind of summarizing?
Therefore we decided that (at least in the current version)
only voice lines can create new events, and
any kind of "semi-event", like in the example above, must be constructed
in a "subtractive" way.
JUST STARTED.
For testing/demonstrating the basic features of the "raw" level,
go to
<SIG>/src/eu/bandm/tscore/test
and execute
make test TESTDATA=<filename>
This will parse the file <filename> and display the results graphically. There are some special test files in this directory.
For testing/demonstrating the higher level features of the CWN instantiation,
go to
<SIG>/src/eu/bandm/music/top
and execute
make test TESTDATA=<filename>
Also in this directory, there is the special make target
make test0
which will parse the file <SIG>/examples/tscore/fuga_a_3.cwn
to create the file ./fuga_a_3.ly
and call lilypond on this file, creating
./fuga_a_3.ps and
./fuga_a_3.pdf.
Have fun!
1 Opposed to other BandM products, the letter "t" does not stand for "typed". Contrarily, the lower layers of tscore try to be as un-typed as possible !-)
2 In future we intend to add other formats, esp. for representing finite mappings, which also can extend vertically instead of horizontally. Nevertheless, this will be additional to this main paradigm of the classical muscial score notation.
3 But note that in "perfect", three-based time measures the meaning may be slightly different, esp. in Renaissance and Baroque style!
|
|
|
|
| introduction | BandM muSig | cwn |
made
2024-09-01_10h36 by
lepper on
happy-ubuntu


produced with
eu.bandm.metatools.d2d
and
XSLT
FYI view
page d2d source text